Prikaži kod
library(mclust)
library(tidyverse)
library(cluster)
library(factoextra)
library(furrr)
library(glue)
library(kableExtra)
library(future.apply)library(mclust)
library(tidyverse)
library(cluster)
library(factoextra)
library(furrr)
library(glue)
library(kableExtra)
library(future.apply)Učitava se kvadratna matrica reda 369 koja predstavlja udaljenosti nizova stanja logova pri čemu je korištena optimal matching metrika.
mat2.om <- readRDS("MAT2_distOM.rds")class(mat2.om)[1] "matrix" "array" dim(mat2.om)[1] 369 369Ova verzija koristi standardni tidyverse pristup s ugniježđenim mutate() i map() funkcijama unutar jednog tibble objekta.
map pozive unutar tibble-a, stvara se veliki memorijski overhead koji značajno usporava izvođenje.calculate_bootstrap_stability <- function(dist_matrix, k_clusters, B_iterations = 200, seed = 123) {
set.seed(seed)
n <- nrow(dist_matrix)
ref_pam <- pam(dist_matrix, k = k_clusters, diss = TRUE)$clustering
ref_agnes <- cutree(agnes(dist_matrix, diss = TRUE, method = "ward"), k = k_clusters)
results <- tibble(iter = 1:B_iterations) %>%
mutate(
u_idx = map(iter, ~ unique(sample(n, replace = TRUE))),
ari_agnes = map_dbl(u_idx, ~ {
d_sub <- dist_matrix[.x, .x]
cl_boot <- cutree(agnes(d_sub, diss = TRUE, method = "ward"), k = k_clusters)
adjustedRandIndex(ref_agnes[.x], cl_boot)
}),
ari_pam = map_dbl(u_idx, ~ {
d_sub <- dist_matrix[.x, .x]
cl_boot <- pam(d_sub, k = k_clusters, diss = TRUE)$clustering
adjustedRandIndex(ref_pam[.x], cl_boot)
}),
sil_agnes = map_dbl(u_idx, ~ {
d_sub <- dist_matrix[.x, .x]
cl_boot <- cutree(agnes(d_sub, diss = TRUE, method = "ward"), k = k_clusters)
ss <- silhouette(cl_boot, d_sub, diss = TRUE)
mean(ss[, "sil_width"])
}),
sil_pam = map_dbl(u_idx, ~ {
d_sub <- dist_matrix[.x, .x]
cl_boot <- pam(d_sub, k = k_clusters, diss = TRUE)$clustering
ss <- silhouette(cl_boot, d_sub, diss = TRUE)
mean(ss[, "sil_width"])
})
)
return(results)
}Optimizirana verzija koja izbjegava kompleksnu strukturu tibble objekta tijekom računanja. Funkcije se izvršavaju unutar obične liste, a tek se na kraju spajaju u tablicu pomoću bind_rows().
calculate_bootstrap_stability_fast <- function(dist_matrix, k_clusters, B_iterations = 200, seed = 123) {
set.seed(seed)
n <- nrow(dist_matrix)
ref_pam <- pam(dist_matrix, k = k_clusters, diss = TRUE)$clustering
ref_agnes <- cutree(agnes(dist_matrix, diss = TRUE, method = "ward"), k = k_clusters)
results_list <- map(1:B_iterations, function(i) {
u_idx <- unique(sample(n, replace = TRUE))
d_sub <- dist_matrix[u_idx, u_idx]
cl_agnes <- cutree(agnes(d_sub, diss = TRUE, method = "ward"), k = k_clusters)
ari_a <- adjustedRandIndex(ref_agnes[u_idx], cl_agnes)
sil_a <- mean(silhouette(cl_agnes, d_sub, diss = TRUE)[, "sil_width"])
cl_pam <- pam(d_sub, k = k_clusters, diss = TRUE)$clustering
ari_p <- adjustedRandIndex(ref_pam[u_idx], cl_pam)
sil_p <- mean(silhouette(cl_pam, d_sub, diss = TRUE)[, "sil_width"])
list(ari_agnes = ari_a, ari_pam = ari_p, sil_agnes = sil_a, sil_pam = sil_p)
})
bind_rows(results_list)
}Vrhunac optimizacije koji koristi furrr paket i future backend za distribuciju zadataka na sve dostupne procesorske jezgre (u ovom slučaju 20 threadova na Intel Ultra Core 7).
plan(multisession). Postoji mali inicijalni trošak (overhead) za pripremu radnih procesora pa je neisplativa za jako mali broj iteracija.calculate_bootstrap_stability_nuclear <- function(dist_matrix, k_clusters, B_iterations = 200, seed = 123) {
set.seed(seed)
n <- nrow(dist_matrix)
ref_pam <- pam(dist_matrix, k = k_clusters, diss = TRUE)$clustering
ref_agnes <- cutree(agnes(dist_matrix, diss = TRUE, method = "ward"), k = k_clusters)
results_list <- future_map(1:B_iterations, function(i) {
u_idx <- unique(sample(n, replace = TRUE))
d_sub <- dist_matrix[u_idx, u_idx]
cl_agnes <- cutree(agnes(d_sub, diss = TRUE, method = "ward"), k = k_clusters)
ari_a <- mclust::adjustedRandIndex(ref_agnes[u_idx], cl_agnes)
sil_a <- mean(cluster::silhouette(cl_agnes, d_sub, diss = TRUE)[, "sil_width"])
cl_pam <- cluster::pam(d_sub, k = k_clusters, diss = TRUE)$clustering
ari_p <- mclust::adjustedRandIndex(ref_pam[u_idx], cl_pam)
sil_p <- mean(cluster::silhouette(cl_pam, d_sub, diss = TRUE)[, "sil_width"])
list(ari_agnes = ari_a, ari_pam = ari_p, sil_agnes = sil_a, sil_pam = sil_p)
}, .options = furrr_options(seed = TRUE))
bind_rows(results_list)
}run_stability_benchmark <- function(dist_matrix, test_ks = c(3, 4), B = 100) {
vremena_lista <- list()
for(k in test_ks) {
message(glue("\n{str_dup('=', 30)}"))
message(glue("POKREĆEM BENCHMARK ZA k = {k} (B = {B})"))
message(glue("{str_dup('=', 30)}"))
# 1. ORIGINALNA FUNKCIJA
message("--> Izvodi se: Originalna metoda...")
t_orig <- system.time({
calculate_bootstrap_stability(dist_matrix, k_clusters = k, B_iterations = B)
})
vremena_lista[[length(vremena_lista) + 1]] <- tibble(k = k, metoda = "Original", vrijeme = t_orig["elapsed"])
# 2. FAST FUNKCIJA
message("--> Izvodi se: Fast (Map) metoda...")
t_fast <- system.time({
calculate_bootstrap_stability_fast(dist_matrix, k_clusters = k, B_iterations = B)
})
vremena_lista[[length(vremena_lista) + 1]] <- tibble(k = k, metoda = "Fast", vrijeme = t_fast["elapsed"])
# 3. NUCLEAR FUNKCIJA
message(glue("--> Izvodi se: Nuclear (Parallel) na {parallel::detectCores() - 2} jezgre..."))
plan(multisession, workers = parallel::detectCores() - 2)
t_nuke <- system.time({
calculate_bootstrap_stability_nuclear(dist_matrix, k_clusters = k, B_iterations = B)
})
plan(sequential)
vremena_lista[[length(vremena_lista) + 1]] <- tibble(k = k, metoda = "Nuclear", vrijeme = t_nuke["elapsed"])
}
# Spajanje rezultata i izračun ubrzanja
res_df <- bind_rows(vremena_lista) %>%
group_by(k) %>%
mutate(speedup = first(vrijeme) / vrijeme) %>%
ungroup()
return(res_df)
}Testiranje svih implementacija na \(1000\) bootstrap uzoraka. U ovom slučaju je testirano za \(k=3\) i \(k=4\) pri čemu je \(k\) zadani broj klastera. Uočite da svaka implementacija na svakom uzorku radi hijerarhijsko i PAM klasteriranje i za svako takvo klasteriranje određuje silhouette svih elemenata u uzorku i prosječnu vrijednost i računa adjusted random index za svako takvo klasteriranje u odnosu na klasteriranje na početnom skupu podataka.
moj_benchmark <- run_stability_benchmark(mat2.om, test_ks = c(3,4), B = 1000)
moj_benchmark %>% kbl(format = "html") %>%
kable_styling(
bootstrap_options = c("hover", "striped", "condensed"),
full_width = FALSE
) %>%
scroll_box(width = "100%")| k | metoda | vrijeme | speedup |
|---|---|---|---|
| 3 | Original | 18.635 | 1.000000 |
| 3 | Fast | 9.757 | 1.909911 |
| 3 | Nuclear | 2.008 | 9.280378 |
| 4 | Original | 20.509 | 1.000000 |
| 4 | Fast | 10.917 | 1.878630 |
| 4 | Nuclear | 2.121 | 9.669496 |
# Filtriramo samo stupac 'vrijeme' za prikaz na grafu
moj_benchmark_long <- moj_benchmark %>%
select(k, metoda, vrijeme) %>%
pivot_longer(cols = vrijeme, names_to = "tip_mjerenja", values_to = "vrijednost")
ggplot(moj_benchmark_long, aes(x = metoda, y = vrijednost, fill = metoda)) +
geom_col(position = "dodge") +
facet_wrap(~k) +
labs(title = "Benchmark performansi",
x = "Metoda",
y = "Vrijeme (s)") +
theme_minimal()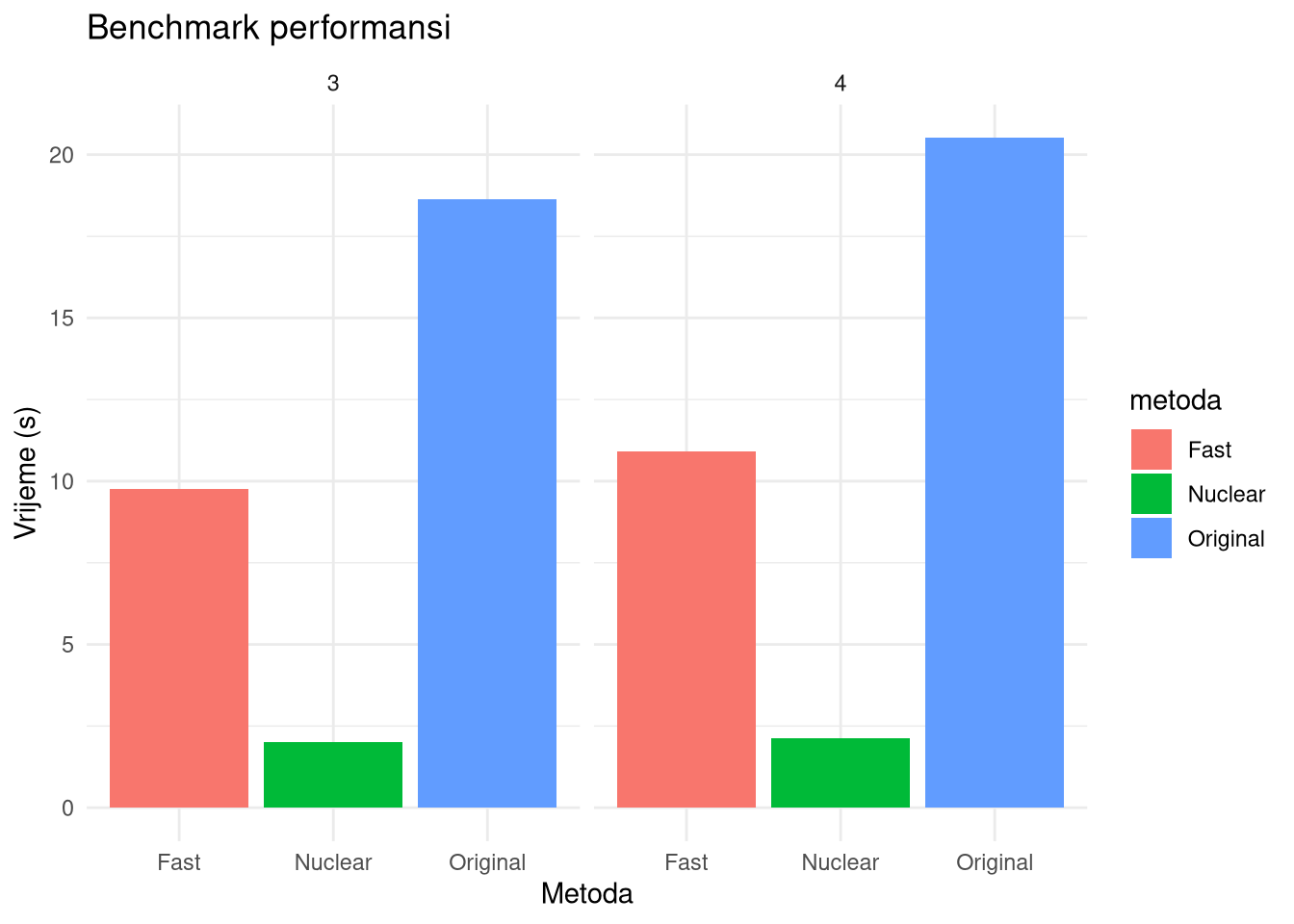
U donjem videu možete vidjeti testiranje nuclear implementacije na \(100\,000\) bootstrap uzoraka. U videu se vidi dodatno GPU opterećenje, ali to je zbog snimanja ekrana. Također, zbog snimanja ekrana, izvršavanje je trajalo malo više, oko 256 sekundi. U normalnim okolnostima izvršavanje je trajalo 193 sekunde. U svakom slučaju impresivna brzina pri čemu se istovremeno računalo može normalno koristiti za neke druge zadatke. Osim dobrog hardvera, zaslužan je i cachyOS.
Status: Nuclear benchmark uspješno završen.
Živio Linux! 🐧 ❄️ (CachyOS)
Sljedeći kod se ovdje ne izvodi, samo se želi pokazati kako se došlo do podataka u rds datotekama.
plan(multisession, workers = parallel::detectCores() - 2)
stab_k3_nuclear <- calculate_bootstrap_stability_nuclear(
mat2.om, k_clusters = 3, B_iterations = 100000)
stab_k4_nuclear <- calculate_bootstrap_stability_nuclear(
mat2.om, k_clusters = 4, B_iterations = 100000)
saveRDS(stab_k3_nuclear, "stab_k3_100k_nuclear.rds")
saveRDS(stab_k4_nuclear, "stab_k4_100k_nuclear.rds")
plan(sequential)Učitavanje podataka iz datoteka
stab_k3_nuclear <- readRDS("stab_k3_100k_nuclear.rds")
stab_k4_nuclear <- readRDS("stab_k4_100k_nuclear.rds")
usporedba_df <- bind_rows(
stab_k3_nuclear %>% mutate(k = "k=3"),
stab_k4_nuclear %>% mutate(k = "k=4")
) %>%
pivot_longer(cols = starts_with("ari_") | starts_with("sil_"),
names_to = "metrika_metoda",
values_to = "vrijednost") %>%
separate(metrika_metoda, into = c("metrika", "metoda"), sep = "_")
ari_means <- usporedba_df %>%
filter(metrika == "ari") %>%
group_by(k, metoda) %>%
summarise(m_val = mean(vrijednost), .groups = "drop")
sil_means <- usporedba_df %>%
filter(metrika == "sil") %>%
group_by(k, metoda) %>%
summarise(m_val = mean(vrijednost), .groups = "drop")Unatoč dobroj geometrijskoj separaciji AGNES metode, visoka stabilnost PAM algoritma pri \(k=4\) (\(\text{ARI} > 0.80\)) potvrđuje ga kao najrobusniji model osiguravajući rezultate koji su otporni na šum i varijacije u uzorku.
ggplot(usporedba_df %>% filter(metrika == "ari"), aes(x = k, y = vrijednost, fill = metoda)) +
geom_violin(alpha = 0.5, position = position_dodge(width = 0.8)) +
geom_boxplot(width = 0.2, position = position_dodge(width = 0.8), outlier.alpha = 0.2) +
stat_summary(fun = mean, geom = "point", shape = 21, size = 3, fill = "yellow", color = "black",
position = position_dodge(width = 0.8), aes(group = metoda)) +
theme_minimal() +
labs(title = "Usporedba stabilnosti (ARI) za k=3 i k=4 (B=100 000)",
subtitle = "Viša vrijednost i manji raspon znače bolju stabilnost",
y = "Adjusted Rand Index", x = "Broj klastera") +
scale_fill_brewer(palette = "Set1")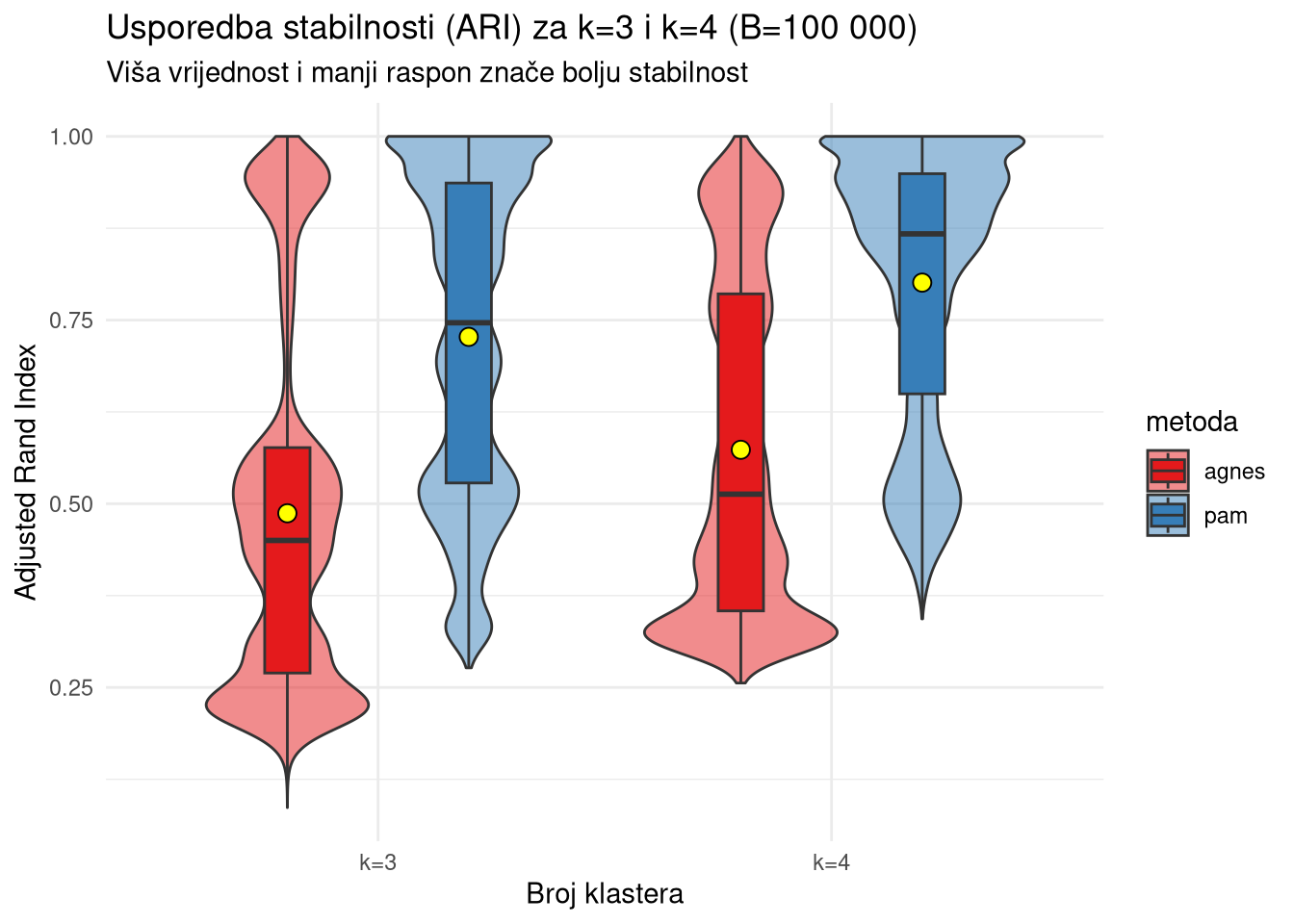
ggplot(usporedba_df %>% filter(metrika == "sil"), aes(x = k, y = vrijednost, fill = metoda)) +
geom_violin(alpha = 0.5, position = position_dodge(width = 0.8)) +
geom_boxplot(width = 0.2, position = position_dodge(width = 0.8), outlier.alpha = 0.2) +
stat_summary(fun = mean, geom = "point", shape = 21, size = 3, fill = "yellow", color = "black",
position = position_dodge(width = 0.8), aes(group = metoda)) +
theme_minimal() +
labs(title = "Usporedba kvalitete (Silhouette) za k=3 i k=4 (B=100 000)",
subtitle = "Viša vrijednost znači jasnije razdvojene klastere",
y = "Average Silhouette Width", x = "Broj klastera") +
scale_fill_brewer(palette = "Set2")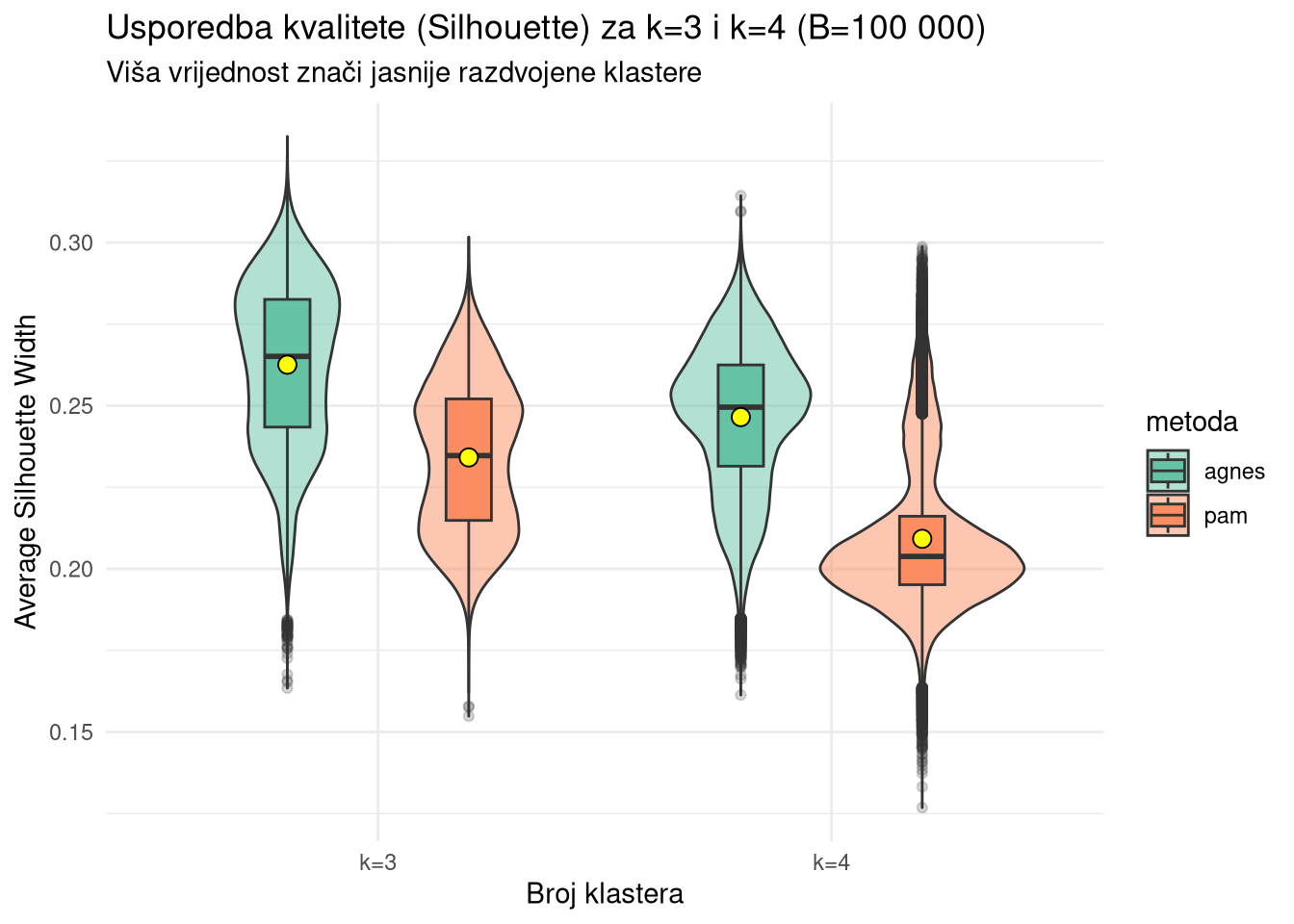
ggplot(usporedba_df %>% filter(metrika == "ari"), aes(x = vrijednost, fill = metoda)) +
geom_histogram(bins = 30, alpha = 0.6, color = "white", position = "identity") +
# Dodavanje vertikalne linije za prosjek
geom_vline(data = ari_means, aes(xintercept = m_val),
linetype = "dashed", size = 0.7) +
# Razdvajanje po k i metodi za preglednost
facet_grid(metoda ~ k) +
theme_minimal() +
scale_fill_brewer(palette = "Set1") +
scale_color_brewer(palette = "Set1") +
labs(title = "Distribucija ARI vrijednosti (B=100 000)",
subtitle = "Isprekidana linija predstavlja aritmetičku sredinu",
x = "Adjusted Rand Index", y = "Frekvencija")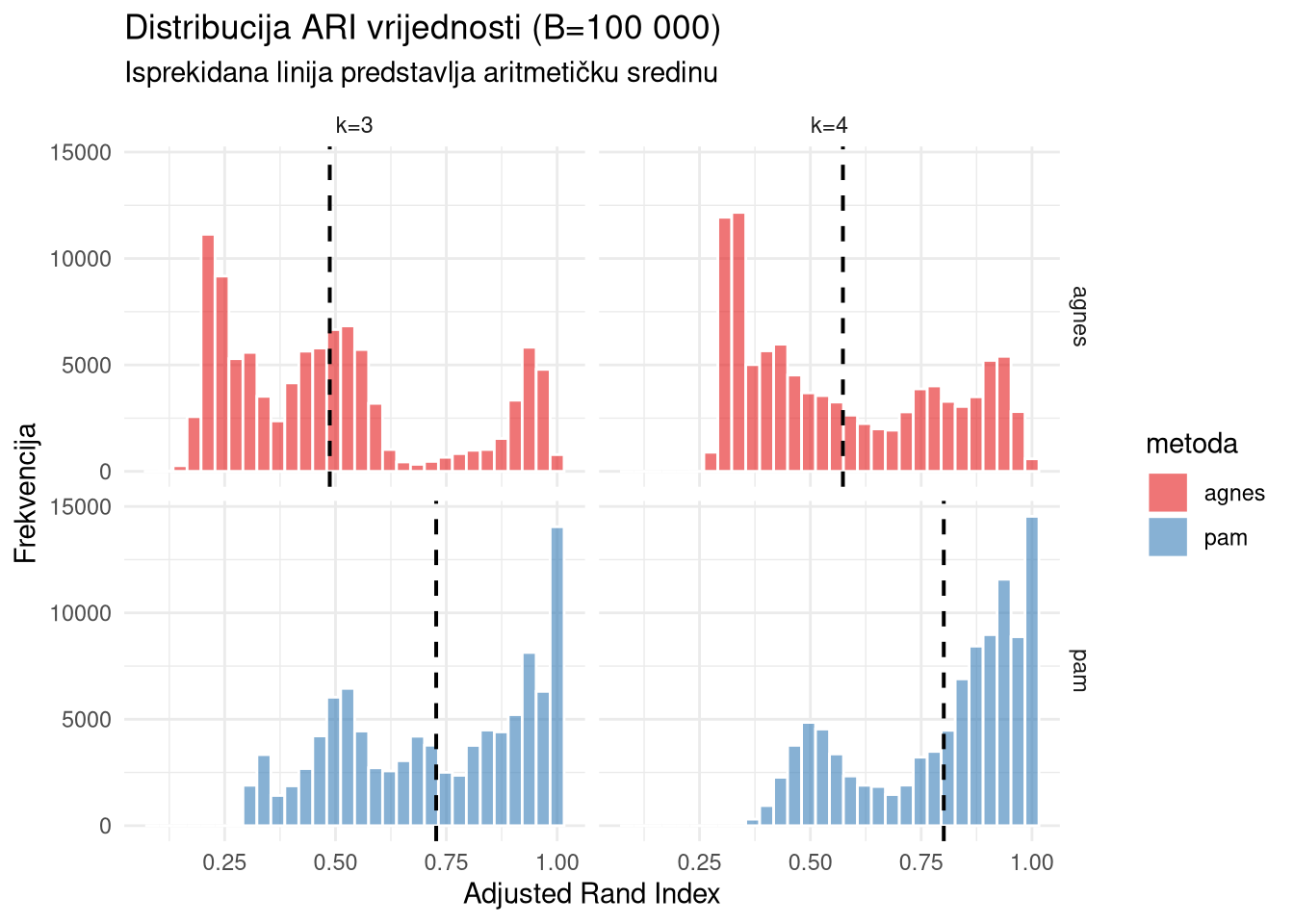
ggplot(usporedba_df %>% filter(metrika == "sil"), aes(x = vrijednost, fill = metoda)) +
geom_histogram(bins = 30, alpha = 0.6, color = "white", position = "identity") +
geom_vline(data = sil_means, aes(xintercept = m_val),
linetype = "dashed", size = 0.7) +
facet_grid(metoda ~ k) +
theme_minimal() +
scale_fill_brewer(palette = "Set2") +
scale_color_brewer(palette = "Set2") +
labs(title = "Distribucija Silhouette Width vrijednosti (B=100 000)",
subtitle = "Isprekidana linija predstavlja aritmetičku sredinu",
x = "Average Silhouette Width", y = "Frekvencija")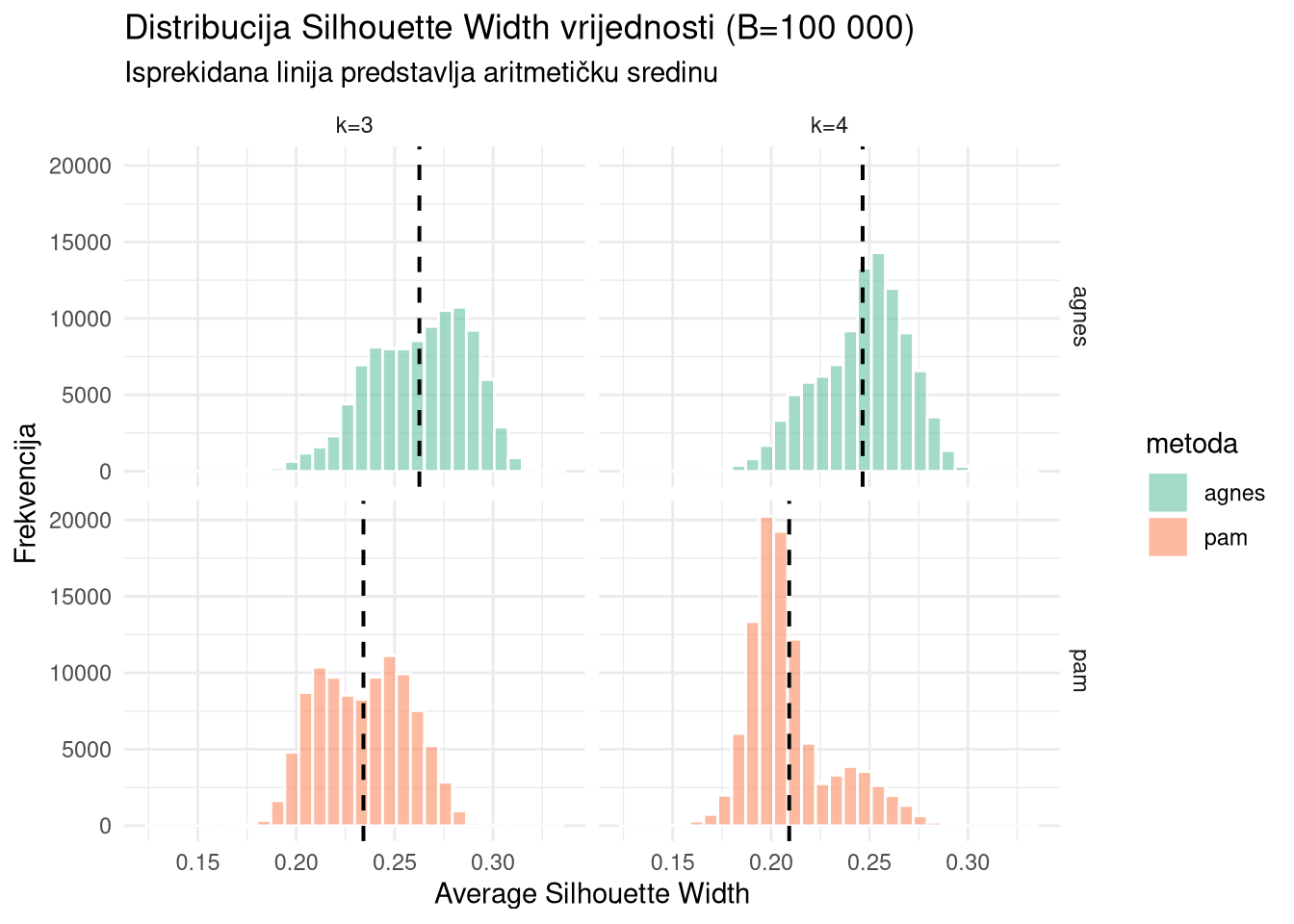
Funkcija calculate_jaccard_mega_nuclear implementira algoritam za procjenu stabilnosti klasteriranja na razini parova elemenata pomoću Jaccardovog indeksa stabilnosti. Glavni koraci implementacije:
Paralelizacija (Map faza). Funkcija automatski prepoznaje broj dostupnih jezgri procesora (koristeći detectCores() - 2) te raspoređuje ukupni broj bootstrap iteracija (\(B=100\,000\)) na više radnih procesa pomoću future.apply biblioteke.
Bootstrap uzorkovanje. U svakoj iteraciji generira se nezavisni bootstrap uzorak. Na tom uzorku paralelno se izvode dva algoritma klasteriranja: PAM (Partitioning Around Medoids) i AGNES (Agglomerative Nesting s Wardovom metodom).
Akumulacija ko-pripadnosti. Za svaki par elemenata prati se:
Izračun stabilnosti (Reduce faza). Konačna Jaccardova vrijednost za svaki par izračunava se kao omjer broja zajedničkih klasteriranja i ukupnog broja zajedničkih pojavljivanja u bootstrapu.
Izlaz funkcije su dvije simetrične matrice (za PAM i AGNES) s vrijednostima u segmentu \([0,1]\). Vrijednost blizu \(1\) označava da se par elemenata gotovo uvijek klasterira zajedno (visoka stabilnost), dok vrijednost blizu \(0\) označava da par gotovo nikada ne završava u istoj grupi, bez obzira na varijacije u uzorku.
calculate_jaccard_mega_nuclear <- function(dist_matrix, k_clusters, B_total = 100000) {
n_workers <- parallel::detectCores() - 2
plan(multisession, workers = n_workers)
n <- nrow(dist_matrix)
ids <- 1:n
# Raspodjela posla na jezgre
tasks <- rep(floor(B_total / n_workers), n_workers)
tasks[1] <- tasks[1] + (B_total %% n_workers)
message(paste("🚀 POKREĆEM MEGA NUCLEAR JACCARD na", n_workers, "jezgri..."))
results <- future_lapply(tasks, function(n_iter) {
# Lokalne matrice (Map faza)
loc_pres <- matrix(0, n, n)
loc_pam <- matrix(0, n, n)
loc_agnes <- matrix(0, n, n)
for(i in 1:n_iter) {
u_idx <- sort(unique(sample(ids, replace = TRUE)))
d_sub <- dist_matrix[u_idx, u_idx]
fit_pam <- pam(d_sub, k = k_clusters, diss = TRUE)$clustering
fit_agnes <- cutree(agnes(d_sub, diss = TRUE, method = "ward"), k = k_clusters)
loc_pres[u_idx, u_idx] <- loc_pres[u_idx, u_idx] + 1
for(j in 1:k_clusters) {
idx_p <- u_idx[fit_pam == j]
if(length(idx_p) > 1) loc_pam[idx_p, idx_p] <- loc_pam[idx_p, idx_p] + 1
idx_a <- u_idx[fit_agnes == j]
if(length(idx_a) > 1) loc_agnes[idx_a, idx_a] <- loc_agnes[idx_a, idx_a] + 1
}
}
return(list(pres = loc_pres, pam = loc_pam, agnes = loc_agnes))
}, future.seed = TRUE)
# REDUCE faza
final_pres <- Reduce(`+`, lapply(results, `[[`, "pres"))
final_pam <- Reduce(`+`, lapply(results, `[[`, "pam"))
final_agnes <- Reduce(`+`, lapply(results, `[[`, "agnes"))
# Jaccard izračun
jaccard_pam <- final_pam / final_pres
jaccard_agnes <- final_agnes / final_pres
jaccard_pam[is.na(jaccard_pam)] <- 0
jaccard_agnes[is.na(jaccard_agnes)] <- 0
diag(jaccard_pam) <- 1
diag(jaccard_agnes) <- 1
plan(sequential)
return(list(pam = jaccard_pam, agnes = jaccard_agnes))
}Funkcija plot_jaccard služi za vizualizaciju outputa kojeg daje funkcija calculate_jaccard_mega_nuclear. Glavne značajke prikaza su:
Sortiranje prema referentnom modelu. Funkcija koristi originalno klasteriranje cijelog uzorka (PAM ili AGNES) kako bi presložila redoslijed elemenata u Jaccardovoj matrici. Ovim se postupkom elementi koji pripadaju istoj grupi grupiraju jedan do drugoga.
Identifikacija strukturnih blokova. Na slici se stabilni klasteri manifestiraju kao tamnoplavi kvadrati duž glavne dijagonale. Što je kvadrat tamniji i oštriji, to je kohezija unutar tog klastera veća kroz svih \(100\,000\) bootstrap uzoraka.
Detekcija rubnih slučajeva. Svijetla ili siva područja unutar plavih blokova ukazuju na “nestabilne” elemente koji često mijenjaju pripadnost klasteru, dok bijela polja izvan glavne dijagonale potvrđuju jasnu razdvojenost između različitih grupa.
plot_jaccard <- function(j_mat, dist_matrix, k, naslov, metoda = "pam") {
# 1. Izračunaj originalno klasteriranje za sortiranje (da dobijemo blokove)
if(metoda == "pam") {
original_fit <- pam(dist_matrix, k = k, diss = TRUE)$clustering
} else {
original_fit <- cutree(agnes(dist_matrix, diss = TRUE, method = "ward"), k = k)
}
# 2. Stvori poredak (order) - prvo svi iz 1. klastera, pa 2., itd.
ord <- order(original_fit)
# 3. Reorganiziraj matricu prema tom poretku
j_sorted <- j_mat[ord, ord]
# 4. Postavi imena (da se tibble ne buni)
colnames(j_sorted) <- 1:ncol(j_sorted)
rownames(j_sorted) <- 1:nrow(j_sorted)
# 5. Pretvori u dugački format za ggplot
as_tibble(j_sorted, rownames = "i") %>%
pivot_longer(-i, names_to = "j", values_to = "vrijednost") %>%
mutate(
# Faktor osigurava da ggplot poštuje redoslijed koji smo zadali u 'ord'
i = factor(i, levels = rownames(j_sorted)),
j = factor(j, levels = colnames(j_sorted))
) %>%
ggplot(aes(i, j, fill = vrijednost)) +
geom_tile() +
# Koristimo "white" do "darkblue" da se jasno vide granice blokova
scale_fill_gradient(low = "white", high = "darkblue", limits = c(0, 1)) +
theme_minimal() +
labs(title = naslov,
x = "Studenti", y = "Studenti",
fill = "Jaccard Index") +
theme(axis.text = element_blank(),
panel.grid = element_blank(),
axis.ticks = element_blank())
}U donjem videu možete vidjeti testiranje calculate_jaccard_mega_nuclear na \(100\,000\) bootstrap uzoraka za \(4\) klastera. U videu se vidi dodatno GPU opterećenje, ali to je zbog snimanja ekrana. Također, zbog snimanja ekrana, izvršavanje je trajalo malo više, oko 219 sekundi. U normalnim okolnostima izvršavanje je trajalo 150 sekundi. U svakom slučaju impresivna brzina pri čemu se istovremeno računalo može normalno koristiti za neke druge zadatke. Osim dobrog hardvera, zaslužan je i cachyOS.
Status: Nuclear benchmark uspješno završen.
Živio Linux! 🐧 ❄️ (CachyOS)
Sljedeći kod se ovdje ne izvodi, samo se želi pokazati kako se došlo do podataka u rds datotekama.
jac3 <- calculate_jaccard_mega_nuclear(mat2.om, k_clusters = 3)
jac4 <- calculate_jaccard_mega_nuclear(mat2.om, k_clusters = 4)
saveRDS(jac3, "jaccard_k3_100k_nuclear.rds")
saveRDS(jac4, "jaccard_k4_100k_nuclear.rds")Učitavanje podataka iz datoteka
jac3 <- readRDS("jaccard_k3_100k_nuclear.rds")
jac4 <- readRDS("jaccard_k4_100k_nuclear.rds")PAM matrice (posebno za \(k=4\)) pokazuju čiste, tamne i oštro definirane kvadrate duž dijagonale s minimalnim “šumom” (bijela polja između klastera). To potvrđuje da su klasteri stabilni i da elementi unutar njih gotovo uvijek završavaju zajedno, bez obzira na varijacije u uzorku.
Dok AGNES na Jaccard matricama pokazuje “mutne” blokove i puno više unutrašnje varijacije (pruge i svjetliji tonovi unutar kvadrata), PAM zadržava visok intenzitet boje. To vizualno objašnjava zašto AGNES ima onako širok raspon i niži prosjek na ARI dijagramima – on jednostavno ne uspijeva konzistentno grupirati “iste” elemente.
Prelazak sa \(k=3\) na \(k=4\) kod PAM metode ne narušava stabilnost; dapače, dodatno izolira specifične podgrupe bez uvođenja kaosa u matricu. Jaccard matrica za PAM \(k=4\) izgleda najprofesionalnije i “najčistije”, što je vizualni ekvivalent visokoj stabilnosti koju smo vidjeli na histogramima.
plot_jaccard(jac3$pam, mat2.om, 3, "PAM Jaccard Consensus Matrix (3 klastera)")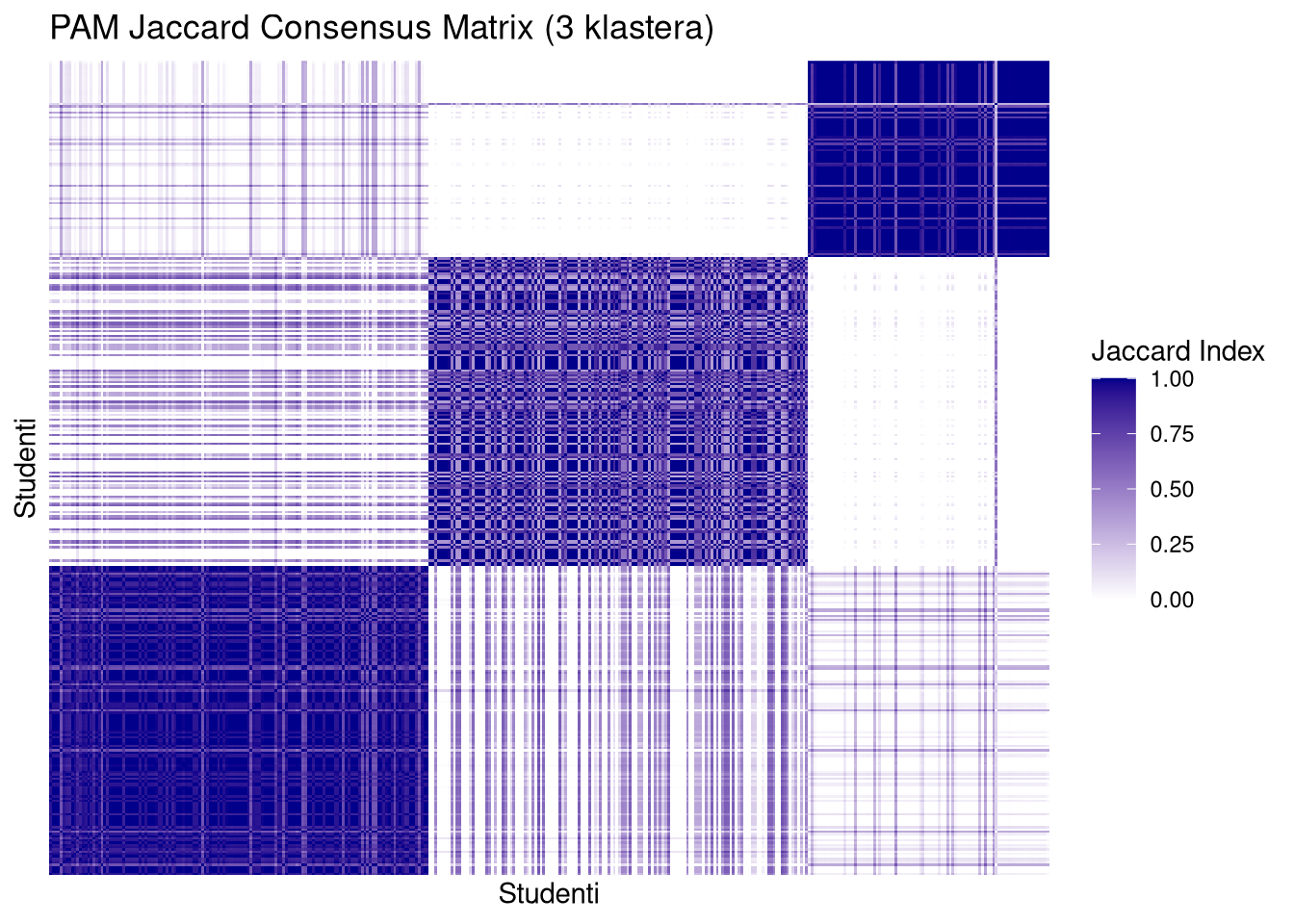
plot_jaccard(jac3$agnes, mat2.om, 3, "Agnes Jaccard Consensus Matrix (3 klastera)", metoda = "agnes")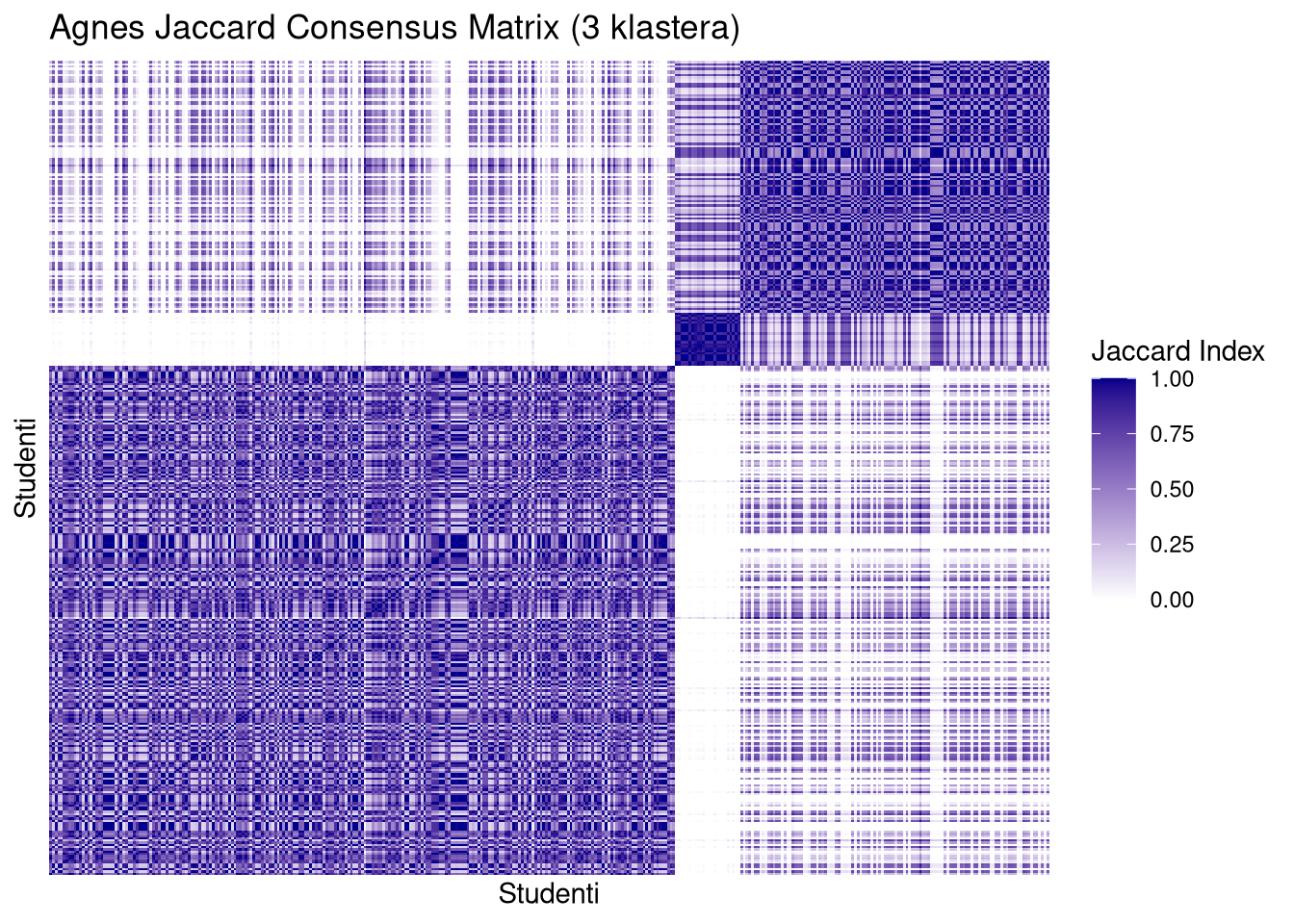
plot_jaccard(jac4$pam, mat2.om, 4, "PAM Jaccard Consensus Matrix (4 klastera)")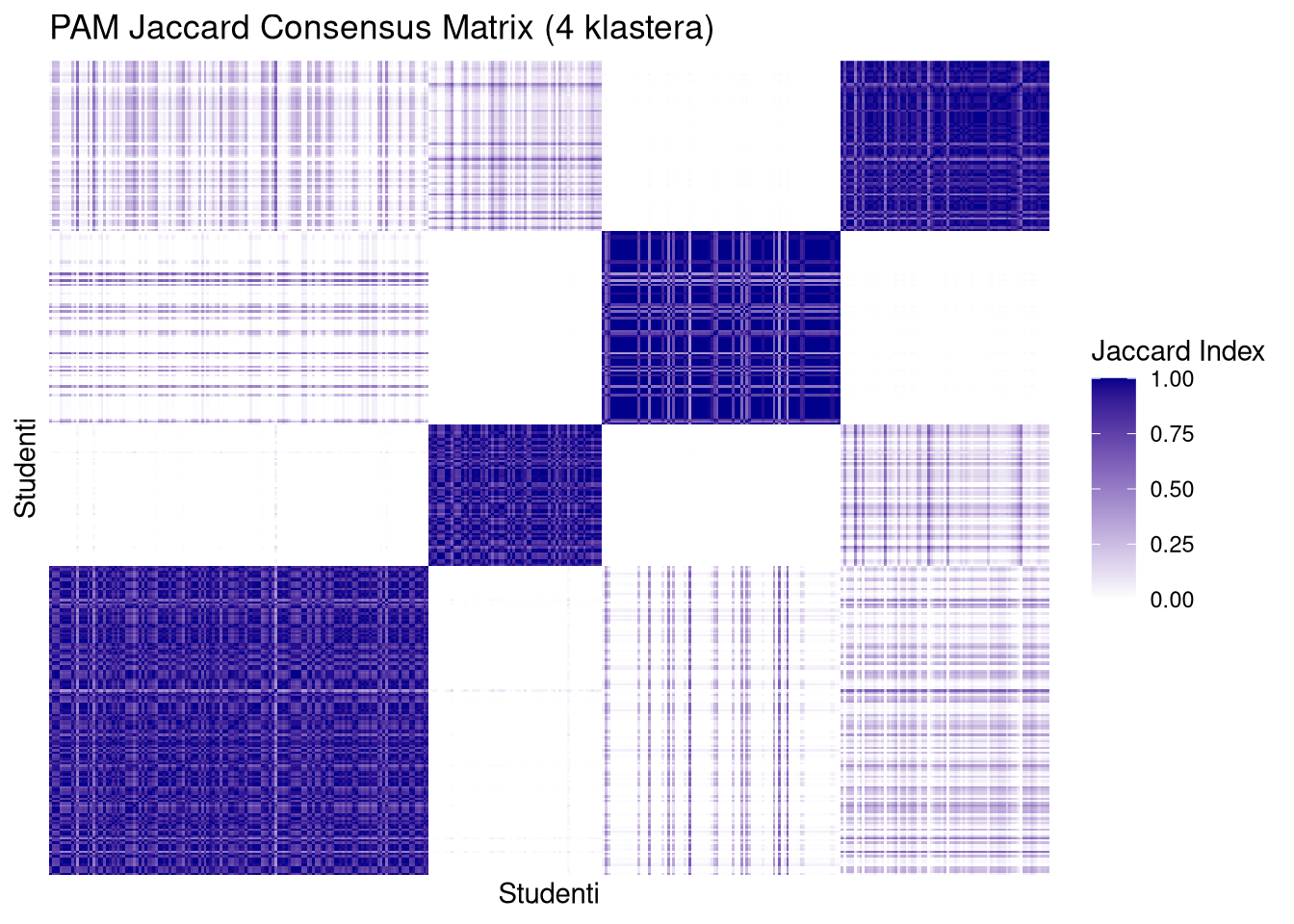
plot_jaccard(jac4$agnes, mat2.om, 4, "Agnes Jaccard Consensus Matrix (4 klastera)", metoda = "agnes")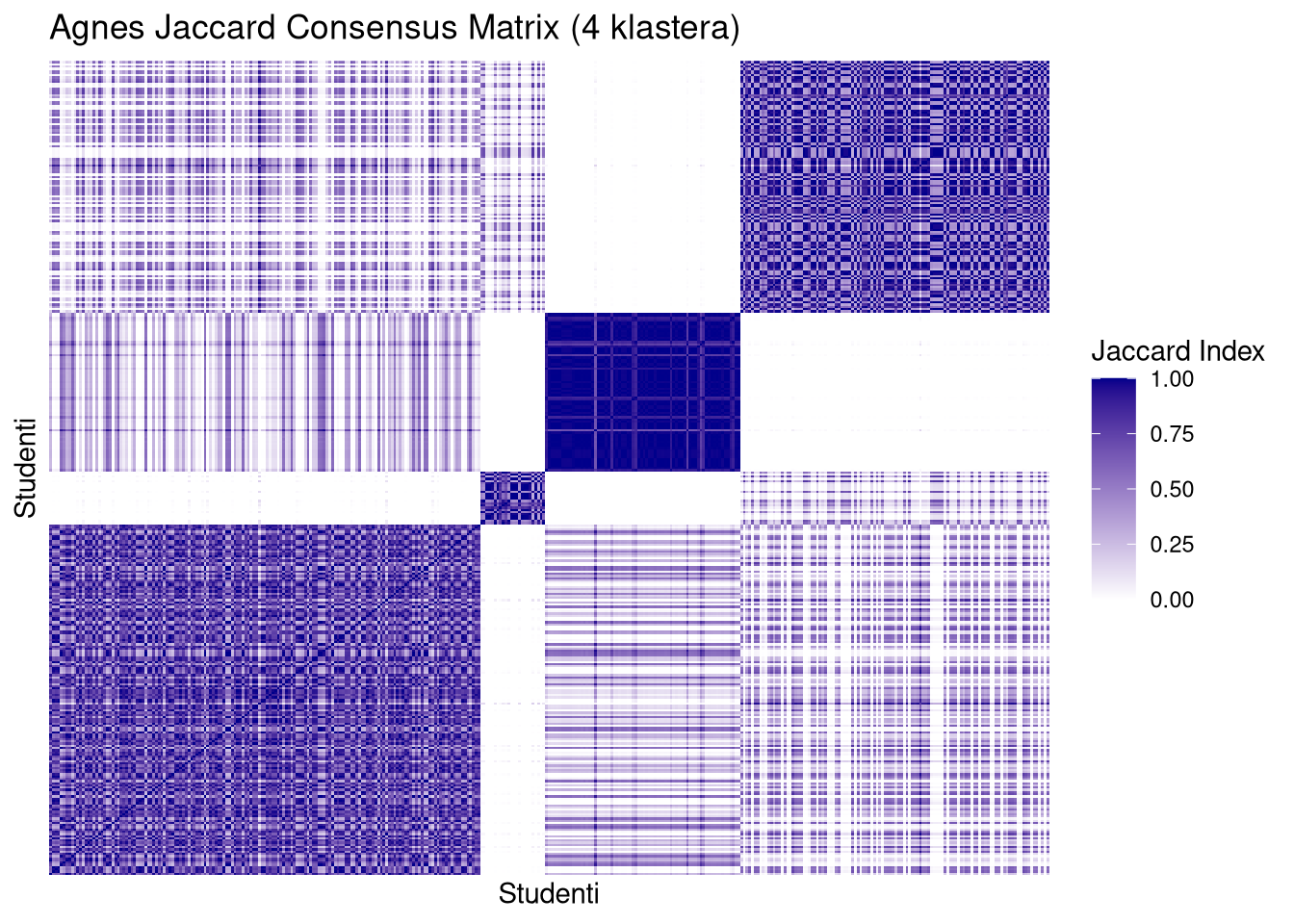
Svi video materijali dobiveni su snimanjem ekrana pomoću Spectacle alata. Međutim, dobiveni video materijali imali su visoku kvalitetu pa ih je trebalo dodatno malo optimizirati za web. U donjem videu možete vidjeti kako je jedan takav dobiveni video od 90MB smanjen u vrlo kratkom vremenu na svega 41MB. Za kratko vrijeme izvođenja opet je zaslužan cachyOS koji je iz mojeg hardvera izvukao maksimum tako što je koristio grafičku karticu. U videu možete vidjeti da je također i CPU bio pod srednjim opterećenjem. U terminalu je korištena sljedeća naredba:
ffmpeg -i klasteriranje.webm \
-c:v h264_qsv \
-global_quality 25 \
-vf "scale=1728:1080,fps=30" \
-an klasteriranje_gpu.mp4Naime, ono što se događa “ispod haube” je sljedeće:
Dekodiranje. webm se otpakira (vjerojatno preko CPU).
Filteri -vf "scale=1728:1080,fps=30". ffmpeg šalje svaki frame procesoru. Procesor mora izračunati nove piksele za scale (skaliranje) i izbaciti/dodati frameove za fps=30. Budući da postoje 22 threada, to radi brzo i zbog toga je u videu vidljivo dodatno opterećenje procesora.
Upload. Te obrađene slike se šalju natrag u GPU memoriju.
Enkodiranje -c:v h264_qsv. Intelov GPU čip uzima te slike i pretvara ih u mp4.
Tijekom izvođenja ffmpeg naredbe speed je bio uglavnom oko 4, što je opet zbog dodatnog opterećenja zbog snimanja ekrana. U normalnim oklonostima (bez snimanja ekrana) speed je uglavnom između 7 i 8 pa je vrijeme izvođenja ffmpeg naredbe isto znatno kraće nego u donjem videu.
Zanimljivost:
Dok bi Windowsi usred rendera vjerojatno odlučili da je “savršeno vrijeme” za Update i restart, CachyOS je upravo završio posao, skuhao kavu i pita: “Jel to sve što imaš?” ☕🐧

Efikasnost pobjeđuje bloatware: CachyOS optimizacija na djelu.